

Introduction to Multimodal learning
Multimodal machine learning represents a significant advancement in artificial intelligence. But what does this term actually mean?
To begin, we need to understand the concept of a "modality." Modality refers to a specific type of data. For instance, visual data includes images and videos, audio data covers sounds and speech, and text data involves written words and symbols. Each type of data provides unique information.
Multimodal deep learning involves the integration of these various types of data to enhance the performance and capabilities of AI systems. This approach allows models to understand and interpret information in a more comprehensive manner, much like humans do. Consider a teacher trying to understand a student's performance. The teacher looks at test scores (text data), observes the student's participation in class (visual data), and listens to the student's questions and answers (audio data). Considering all these different pieces of information, the teacher can get a better understanding of the student's strengths and areas for improvement.
Similarly, multimodal deep learning aims to replicate this holistic approach by leveraging different types of data to improve the performance of AI systems.
Before AI can reach the level of general intelligence that many fear, it must first become multimodal. This involves understanding and processing various modalities of data to create a more nuanced and accurate representation of the world.
Human Multimodality
Humans naturally process and integrate information from multiple senses to navigate the world effectively. This ability to combine various sensory inputs is known as multimodality. Our brains are wired to merge information from sight, sound, touch, taste, and smell, creating a cohesive understanding of our surroundings.
In day-to-day communication, more than 70% of information is conveyed non-verbally through gestures, tone of voice, eye movements, and body positioning. These non-verbal cues play a crucial role in understanding emotions and intentions. Our brains seamlessly fuse these inputs with spoken words to grasp the whole meaning of a conversation. For instance, a friend's reassuring smile can enhance the comforting words they speak, making us feel more at ease.
In AI, the goal is to emulate this human capability of multimodal integration. AI systems aim to combine different types of data—such as images, sounds, and text—to create a more nuanced and accurate understanding of various tasks. Just as humans use multiple senses to interpret their environment, multimodal AI strives to process and synthesize diverse data sources to perform complex functions.
Types of data in Multimodal learning
In multimodal learning, understanding the different types of data is crucial. Each type of data, or modality, brings unique information to the table, allowing AI systems to create a fuller picture of the tasks they need to perform. Here are the main types of data involved in multimodal learning:
Visual data: This includes images and videos. Visual data is represented as matrices of pixel values. For example, an image is made up of pixels, each with its own color value. In AI, visual data is often processed using convolutional neural networks (CNNs). CNNs are a type of deep learning model specifically designed to analyze visual data by automatically detecting patterns and features within images. They excel at tasks like image classification, where the model identifies objects within an image, object detection, which involves locating objects within an image, and image generation, where new images are created based on learned patterns.
Audio data: Sounds and speech recordings fall under audio data. This type of data is usually represented as sequences of measurements over time, capturing the amplitude and frequency of sound waves. Audio data can be transformed into spectrograms, which are visual representations of the spectrum of frequencies in a sound signal. Techniques like recurrent neural networks (RNNs) are often used to handle audio data. RNNs are a type of deep learning model designed to recognize patterns in sequences of data by maintaining a 'memory' of previous inputs. This makes them particularly well-suited for tasks like speech recognition and audio classification. Long short-term memory (LSTM) networks are a special kind of RNN capable of learning long-term dependencies, which helps them remember information for longer periods and perform better on tasks that require understanding of context over time.
Text data: Text data includes written words and symbols. In AI, text is often converted into numerical representations called embeddings, which capture the semantic meaning of words. Transformers, such as the models behind GPT-3 and GPT-4, are particularly effective at processing text data. These models have achieved state-of-the-art performance in various natural language processing tasks, including text generation, translation, and sentiment analysis.
Each of these data types has its own characteristics and requires specific methods for effective processing. For example, images have spatial structures that are crucial for interpretation, while audio data has temporal sequences that convey important information. Text data, on the other hand, involves discrete elements (words) that must be understood in context.
In multimodal learning, the challenge lies in integrating these diverse data types to build models that can leverage the strengths of each modality. For instance, combining visual and audio data can improve speech recognition in noisy environments. Similarly, integrating text descriptions with images can enhance image generation or captioning tasks.
Techniques for data fusion in Multimodal learning
Data fusion techniques are essential for integrating different types of data into a cohesive model. Here are the main approaches used:
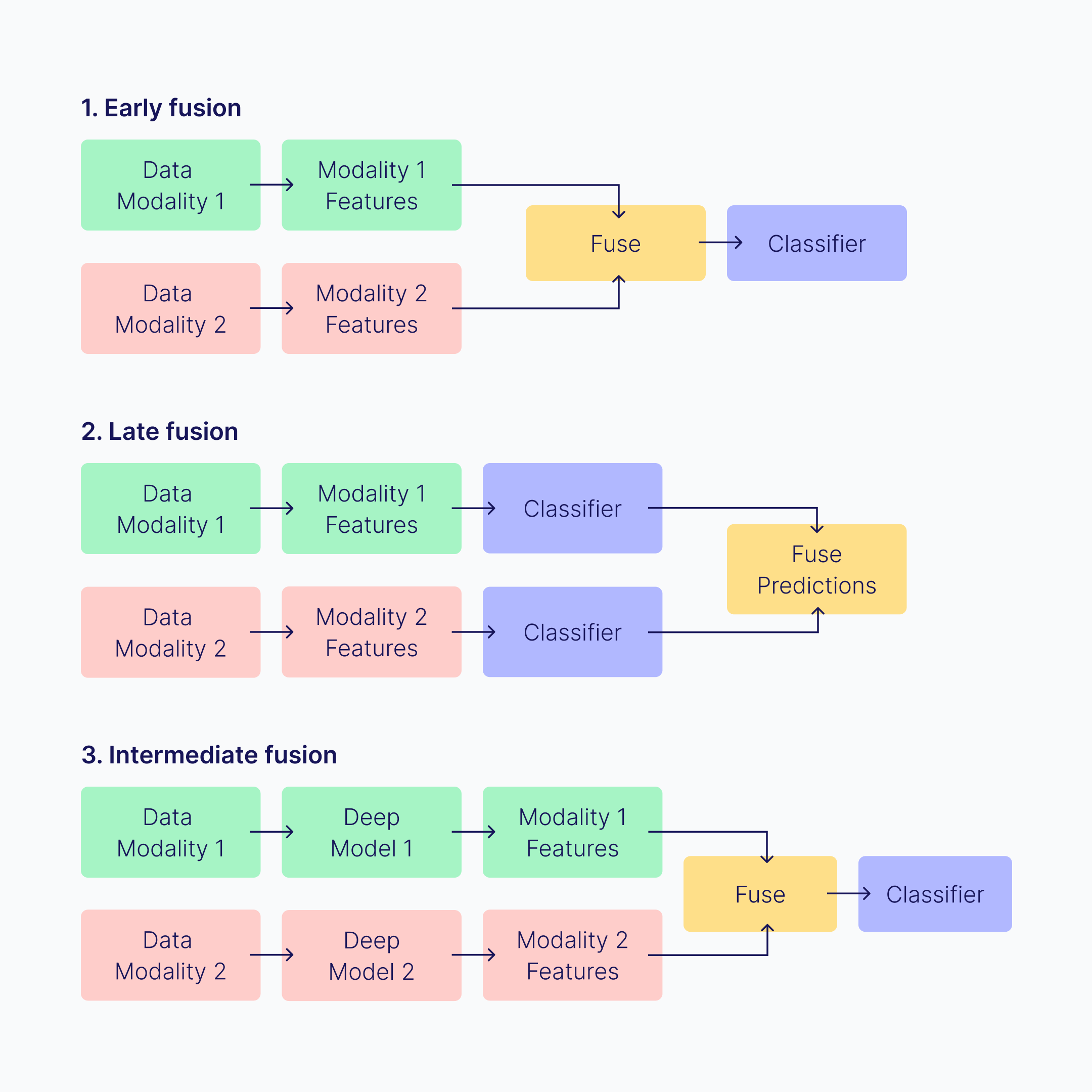
Early fusion: This method involves combining features from different modalities at the very beginning of the process. For instance, visual and audio data are merged before being input into the model. Early fusion can be simple, often just joining the data together. It has the advantage of being easy to implement and allows the model to learn inter-modal correlations early on. However, it may lose some unique characteristics of each modality, particularly if the data types are vastly different, like temporal (audio) and spatial (images).
Late fusion: This approach processes each modality independently using separate models. After these models make their predictions, the results are combined. This combination can be done using techniques like voting, where the most common prediction is chosen, or weighted sums, where predictions are given different levels of importance.
Late fusion keeps the unique characteristics of each type of data because they are processed separately before being merged. However, it may not fully capture the interactions between the different types of data and often requires more computational power since multiple models need to be trained. Let's understand, with a use case example, imagine an AI system that identifies movie genres. One model analyzes the movie poster (visual data), another listens to the trailer (audio data), and a third reads the movie synopsis (text data). Each model makes its own prediction, and the system then combines these predictions to determine the most likely genre.
Hybrid fusion: Hybrid fusion combines elements of both early and late fusion. For example, visual and audio data might be combined early, processed through a model, and then combined with text data at a later stage. This flexible approach can be tailored to specific use cases, leveraging the advantages of both early and late fusion. It's commonly used in scenarios where multiple types of data are present, like social media content that includes images, audio, and text.
Each of these fusion techniques has its strengths and weaknesses, and the choice of method depends on the specific requirements of the task at hand. Early fusion is straightforward and quick but can struggle with modality-specific nuances. Late fusion preserves these nuances but demands more computational resources. Hybrid fusion offers flexibility, and attention-based fusion provides dynamic adaptability.
Challenges in Multimodal deep learning
Multimodal deep learning is a powerful approach, but it comes with its own set of challenges. It's important to understand these obstacles in order to create AI systems that are effective and efficient across multiple modes of operation.
Complexity: Designing systems that can handle multiple types of data is inherently more complex than single-modal systems. Each modality has unique properties and requires different processing techniques. Integrating these various methods into a single coherent model can be challenging. This complexity often leads to longer development times and increased difficulty in debugging and maintaining the system.
Feature compatibility: Different types of data have unique characteristics. Images have spatial properties, audio has time-based sequences, and text consists of discrete elements. Combining these different features meaningfully is challenging. It requires advanced techniques to adjust and transform the data so they can be processed together without losing their specific details.
Data synchronization: Ensuring that data from different modalities is properly synchronized is critical. For instance, in audio-visual speech recognition, the audio and video inputs must be perfectly aligned. Any misalignment can lead to inaccurate results. Achieving this level of synchronization often requires precise data collection methods and careful preprocessing.
Computational power: Multimodal models typically require more computational resources than single-modal models. This is because they often involve multiple processing steps, such as separate models for each modality and complex fusion mechanisms. Training these models can be time-consuming and expensive, requiring powerful hardware and significant computational resources.
Moreover, attention mechanisms have become a crucial tool in multimodal learning. An attention mechanism is a technique that helps the model focus on the most important parts of the input data at any given time. This dynamic focus improves the integration of different types of data. For example, in environments with high background noise, the model can prioritize visual information over audio to maintain performance.
Addressing the challenges in multimodal learning requires a multifaceted approach. Researchers are continually innovating to find better ways to combine different types of data, synchronize inputs, and reduce computational demands. These efforts are essential for developing more robust and capable multimodal AI systems.
Real-world applications of Multimodal learning
Multimodal learning isn't just a theoretical concept. It's already being applied in various real-world scenarios, enhancing the capabilities of AI systems in significant ways.
Generative fill in Photoshop: One fascinating application is Adobe Photoshop's generative fill feature. This tool allows users to select part of an image and prompt the AI to generate new content within that selection. For example, if you select a blank area in an image and request a ship and a sea, the AI generates a realistic image, including details like the ship's reflection in the sea. This application demonstrates how visual data can be manipulated and augmented using advanced AI techniques.
Visual question answering systems: Another intriguing application is visual question answering (VQA) systems. These systems take an image as input and allow users to ask questions about the content of the image. For instance, you could upload a photo and ask, "What objects are in this image?" or "What would happen if I removed this item?" The AI analyzes the visual data and provides responses based on its understanding of the image. This technology is advancing rapidly and is expected to be integrated into tools like ChatGPT, enhancing its capabilities with visual understanding.
Multimodal capabilities in ChatGPT: ChatGPT has evolved to incorporate multimodal capabilities, meaning it can now handle tasks involving both text and images. For instance, you can upload a photo of a house and ask ChatGPT to suggest renovation ideas. Similarly, you can provide an image of a recipe and ask for a step-by-step cooking guide. This integration of text and visual data makes ChatGPT more versatile and useful in everyday tasks.
These advancements are making AI systems more interactive and capable, allowing them to perform complex tasks that were previously difficult or impossible.
As multimodal learning continues to develop, we can expect to see even more innovative applications across various fields, from healthcare to entertainment. These technologies are enhancing the functionality of existing tools and paving the way for new and exciting possibilities in AI.
Future directions in Multimodal learning
The future of multimodal learning is promising, with advancements poised to make AI systems even more powerful and versatile. As technology continues to evolve, several key areas are likely to see significant progress.
Integration of more modalities: One of the most exciting developments will be the incorporation of additional modalities beyond the common trio of visual, audio, and text data. For example, integrating haptic (touch) feedback could revolutionize fields like virtual reality and robotics, allowing machines to interact with their environment in more human-like ways. Sensing and processing environmental data, such as temperature and humidity, could also enhance AI applications in smart homes and environmental monitoring.
Enhanced AI capabilities: As multimodal learning techniques improve, AI systems will become better at understanding and responding to complex situations. This means more accurate and context-aware interactions. For instance, an AI assistant could understand not just the words being spoken but also the speaker's emotional tone and body language, leading to more nuanced and effective responses.
Advanced fusion techniques: Researchers will continue to develop more sophisticated methods for combining data from different modalities. This includes refining attention-based fusion techniques that allow AI systems to dynamically focus on the most relevant data. Improved fusion methods will help create AI models that are not only more accurate but also more efficient, reducing the computational power required.
Real-world applications: The practical applications of multimodal learning will expand significantly. In healthcare, AI could integrate patient records, medical images, and real-time monitoring data to provide comprehensive diagnostics and treatment plans. In education, multimodal AI could create interactive and personalized learning experiences that adapt to students' needs. The entertainment industry could see more immersive and interactive experiences, with AI-generated content that seamlessly combines visuals, sound, and narrative.
Ethical and responsible AI: As multimodal learning technologies advance, there will be a greater focus on ensuring that these systems are developed and used ethically. This includes addressing concerns about privacy, bias, and transparency. Ensuring that AI systems are fair and unbiased, especially when they integrate multiple types of data, will be crucial. Researchers and developers will need to establish guidelines and best practices for ethical AI development and deployment.
As we look to the future, it is clear that multimodal learning will play a key role in advancing AI capabilities, leading to smarter, more adaptable, and more intuitive systems. The ongoing research and innovation in this field promise to unlock new possibilities and transform various industries, making AI an even more integral part of our daily lives.