

The biggest worry about training AI models with customer data is privacy concerns, and federated learning architecture gracefully addresses these concerns. Traditional AI training relies on centralized datasets, which expose sensitive information to significant risks, including data breaches, unauthorized access, and non-compliance with regulations like GDPR and CCPA. These vulnerabilities make it challenging for organizations to balance the need for advanced AI solutions with protecting user data. Federated learning offers a transformative solution, enabling AI training while safeguarding user privacy. In this blog, we will explore the challenges of traditional AI and how federal learning architecture resolves these challenges. We will also see how this architecture works and examine real-world examples of federated learning.
Challenges of traditional AI training techniques
Sharing data for AI training comes with serious privacy and ethical concerns. Even anonymized data can sometimes be traced back to individuals, putting them at risk of breaches or misuse. Organizations may also use data in ways users disagree, leading to concerns about targeted ads, unethical AI, or even surveillance.
Data breaches add another layer of risk, as users can lose control of their information, often with permanent consequences. On top of that, many companies aren’t transparent about how they handle data, making it hard to hold them accountable. While businesses gain enormous value from user data, users often get little in return.
The traditional approach to AI training often requires collecting and centralizing vast amounts of data from users and devices into a single server. While this centralization enables robust machine learning, it also introduces significant privacy, security, and compliance risks:
-Data breaches Centralized datasets are vulnerable to cyberattacks, risking exposure of sensitive data, identity theft, and reputational harm (e.g., healthcare data leaks).
-Regulatory non-compliance: Centralized data storage often violates privacy laws like GDPR and CCPA, especially principles like "data minimization" and "purpose limitation."
-Unintended inferences: AI models may infer private details (e.g. user habits) from non-sensitive data, worsening privacy concerns.
-Ethical concerns: Lack of transparency in data usage erodes trust and raises ethical issues about consent and ownership.
What is federated learning architecture?
Federated Learning (FL) is a way to train AI models without collecting users’ raw data. Instead of gathering data in one central place, FL keeps the data on users' devices, like smartphones or IoT gadgets. The model learns locally on each device using the data stored there. Once the training is complete, only the model updates (like improved settings or patterns) are shared with a central server, not the actual data.
These updates from many devices are combined, or "aggregated," on the server to improve the overall AI model. This process keeps repeating, improving the model while protecting user privacy. FL is designed to ensure that sensitive information never leaves the user’s device, making it a secure and privacy-friendly approach.
By decentralizing training, FL helps reduce the risks of data breaches and aligns with privacy laws like GDPR. It’s especially useful for applications like predictive keyboards or personalized recommendations, where the AI can learn from users without exposing their private information.
How federated learning works
The process of federated learning can be summarized in these steps:
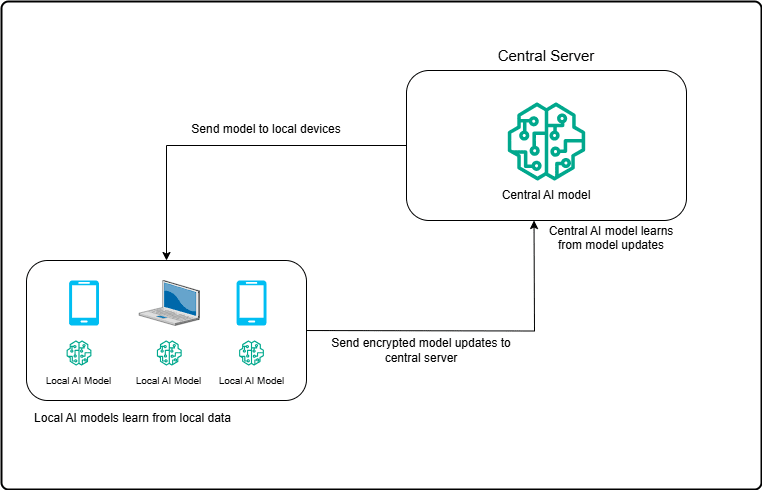
1-Local training on devices: The AI model is sent to multiple user devices, where it learns from local data.
2-Model updates only: Instead of sharing raw data, devices send encrypted updates (like weight adjustments) back to the central server.
3-Aggregated model improvement: The central server aggregates updates from all devices to improve the global AI model.
4-Iterative training: The updated global model is sent back to devices, and the process repeats until the model is optimized.
Now, let's look at the technologies that facilitate this federated learning architecture.
Understanding federated learning architecture technologies
Federated learning is changing how we train AI models by letting devices like smartphones, wearables, and IoT gadgets learn together without sharing raw data. But what makes it all work? Let’s break down the three key technologies behind this process: Federated Averaging, Differential Privacy, and Secure Aggregation.
- Federated averaging: Smarter collaboration
Imagine your phone learning to predict your text typing habits while chatting with other phones worldwide to create a shared model, but without ever sharing your data. That’s what the Federated Averaging algorithm does.
Here’s how it works:
-Each device trains a model using its local data.
-Instead of sending the data, the device sends only updates (like improvements to the model) to a central server.
-The server averages these updates to build a better global model and sends it back to devices for the next round of training.
Why is this a smart solution? It minimizes the amount of data that needs to be shared and allows millions of devices to contribute without overwhelming the system.
- Differential privacy: Keeping things private
No one likes the idea of their data being exposed, even in a shared learning setup. That’s where Differential Privacy comes in. This method adds a bit of randomness (noise) to the updates before they leave your device. Think of it as a protective blur that makes it nearly impossible to trace anything back to you.
A balance is struck between privacy and accuracy. Too much noise might reduce the model's quality, while too little could risk privacy. But when done right, it keeps sensitive details safe while still creating a useful global model.
For example, search engines use this technique to figure out trends without revealing individual user queries. It’s a win-win for privacy and functionality!
- Secure aggregation: Protecting your updates
Even if your updates are safe on your device, what happens when they’re sent to the server? This is where Secure Aggregation steps in to make sure no one can peek at your updates during transmission.
Here’s how it works:
-Before updates leave your device, they’re encrypted.
-When all updates reach the server, the system combines them into a single aggregated result without ever seeing individual updates.
-This way, even if someone intercepts the data, it’s just scrambled gibberish to them.
In sensitive fields like healthcare, this technology ensures patient data stays private while still helping to train smarter models.
Bringing it all together
These three technologies, Federated Averaging, Differential Privacy, and Secure Aggregation, form the backbone of federated learning. Together, they let devices learn collaboratively, keep data private, and secure updates during transmission.
As a result, we get smarter models without compromising security or privacy, making federated learning ideal for applications like personalized healthcare, predictive keyboards, and more. It’s a simple idea with powerful tools working behind the scenes to keep your data safe while building something better for everyone.
How federated learning addresses privacy concerns
Federated learning directly tackles the privacy and compliance challenges inherent in traditional AI training by rethinking the flow and use of data. Below are the key methods that are used in federated learning architecture to address these concerns:
1- Data stays local
In federated learning, raw data never leaves user devices. By keeping sensitive information localized, the architecture minimizes the risk of breaches and unauthorized access. This ensures personal data, such as health records or browsing habits, remains private and inaccessible to external entities.
2- Compliance with privacy regulations
Federated learning architecture is designed to align with stringent privacy laws like GDPR and CCPA:
- Data minimization: Since only model updates are shared, the amount of transmitted data is drastically reduced.
- Purpose limitation: Data is used strictly for local training, ensuring compliance with the intended purpose outlined by privacy laws
- User consent: Federated models can implement mechanisms to ask for user consent before local data is used for training.
3- Protection against inference attacks
Federated learning integrates techniques like differential privacy, which adds carefully calibrated noise to model updates. This ensures that attackers cannot reverse-engineer individual data points, even if they gain access to the aggregated updates.
4- Encryption and secure communication
The model updates sent from devices to the central server are encrypted through techniques like secure aggregation. This ensures that even during transmission, data remains unintelligible to unauthorized parties
5- Decentralized decision-making for added security
By decentralizing the AI training process, federated learning reduces reliance on a single point of failure. Even if a single device is compromised, it does not jeopardize the entire dataset, as the central server does not store sensitive information.
Real-world applications of federated learning
Federated learning has already proven its potential across various industries. By enabling AI models to learn from decentralized, private datasets, it bridges the gap between powerful data-driven insights and strict privacy requirements. Here are some real-world practical use cases that benefit from federated learning:
- Healthcare: Training AI models without exposing patient data
In healthcare, data privacy is paramount due to the sensitivity of patient records. Federated learning architecture allows institutions to collaboratively train models without sharing raw medical data.
-Diagnostic model training: Hospitals can use FL to train diagnostic models (e.g., cancer detection algorithms) using localized patient data while staying compliant with privacy regulations like HIPAA.
-Drug discovery: Drug discovery can benefit from training on a wider dataset without exposing proprietary information.
- Finance
The financial sector deals with highly sensitive user information, including transaction records and account details.
-Fraud detection: Federated learning can analyze patterns across multiple banks or financial institutions without sharing raw transaction data. This collaborative effort improves fraud detection models without compromising client confidentiality.
-Personalized banking: Banks can develop tailored AI models to offer customer-specific financial advice without moving private data to centralized servers.
- Consumer technology
Federated learning powers many modern consumer tech applications by training AI models locally on user devices.
-Predictive text and autocorrect: Google’s Gboard uses FL to refine typing suggestions without uploading user keystrokes to a central server.
-Voice assistants: FL improves virtual assistants like Google Assistant, enabling them to adapt to individual speech patterns while keeping audio data private.
-Recommendations: Streaming platforms or e-commerce services can use FL to personalize suggestions without accessing user history.
- Retail: Demand forecasting and inventory management
Retailers can use federated learning to optimize inventory by analyzing localized customer purchasing patterns. This reduces overstocking and shortages without sharing sensitive sales data between branches or partners.
- Autonomous vehicles and IoT
Connected devices and autonomous cars require massive data to improve functionality, but transmitting such data to central servers introduces risks.
-Autonomous driving systems: Federated learning architecture allows vehicles to improve navigation algorithms collectively by sharing model updates, not raw data, enhancing safety and privacy.
-IoT devices: Smart home systems can use FL to tailor device functionality to user preferences while keeping personal usage data secure.
- Healthcare: Training AI models without exposing patient data
Challenges of federated learning architecture and how to overcome them
Federated learning architecture is a powerful and privacy-preserving AI training method, but it comes with challenges that need thoughtful solutions. Here’s a quick look at the key issues and how they are tackled:
- Data heterogeneity: FL deals with diverse and imbalanced data across devices, which can lead to inconsistent model performance. Refining algorithms like Federated Averaging (FedAvg) and using techniques like personalization layers or multi-task learning can help models better adapt to varying datasets.
- Communication overhead: Frequent communication between devices and the server can cause delays and high bandwidth usage, especially in large-scale setups. This can be minimized with compressed updates, quantization, sparsification, and asynchronous communication to keep training efficient.
- Privacy and security risks: Although federated learning keeps raw data on devices, threats like model inversion or data poisoning remain. Using differential privacy, secure multi-party computation, and anomaly detection can strengthen security and protect the system.
- Device resource constraints: Many devices in federated learning, like smartphones or IoT gadgets, have limited power, memory, and battery life. Lightweight models, energy-efficient algorithms, and cloud-based offloading for intensive tasks can reduce the strain, allowing devices to join only when they meet resource thresholds.
- Scaling and coordination: Managing many devices is tricky, especially with dropouts due to connectivity or resource limits. Scalable systems with robust aggregation methods and task reassignment strategies can ensure smooth training despite interruptions.
By addressing these challenges, federated learning architecture can become a scalable, secure, and privacy-first solution for modern AI systems.